Hardening php.ini cho Shared Hosting: Bảo mật và Tối ưu Apache & PHP-FPM trên Ubuntu 20.04+

Hardening php.ini cho Shared Hosting: Bảo mật và Tối ưu Apache & PHP-FPM trên Ubuntu 20.04+
Document này trình bày cách harden php.ini cho môi trường Shared Hosting chạy trên stack Apache và PHP-FPM trên Ubuntu 20.04+. Nội dung tập trung vào quản lý cấu hình PHP và OPcache thông qua php.ini để tăng cứng an ninh và tối ưu hiệu suất, phù hợp với hệ thống chia sẻ tài nguyên và yêu cầu bảo mật nghiêm ngặt.
Giới thiệu
Trong mô hình Shared Hosting, PHP được vận hành giữa Apache hoặc Nginx và PHP-FPM. Việc cấu hình và làm cứng php.ini đóng vai trò then chốt để giảm thiểu rủi ro từ dữ liệu người dùng và tối ưu hiệu suất phục vụ cùng lúc nhiều người dùng. Các yếu tố liên quan tập trung vào cách PHP xử lý dữ liệu người dùng, bảo mật báo cáo lỗi và đặc biệt tối ưu hóa thông qua OPcache. Tài liệu tham khảo choOPcache và các tham số PHP được trình bày trong phạm vi Runtime Configuration của PHP.
Kiến trúc và khái niệm cốt lõi
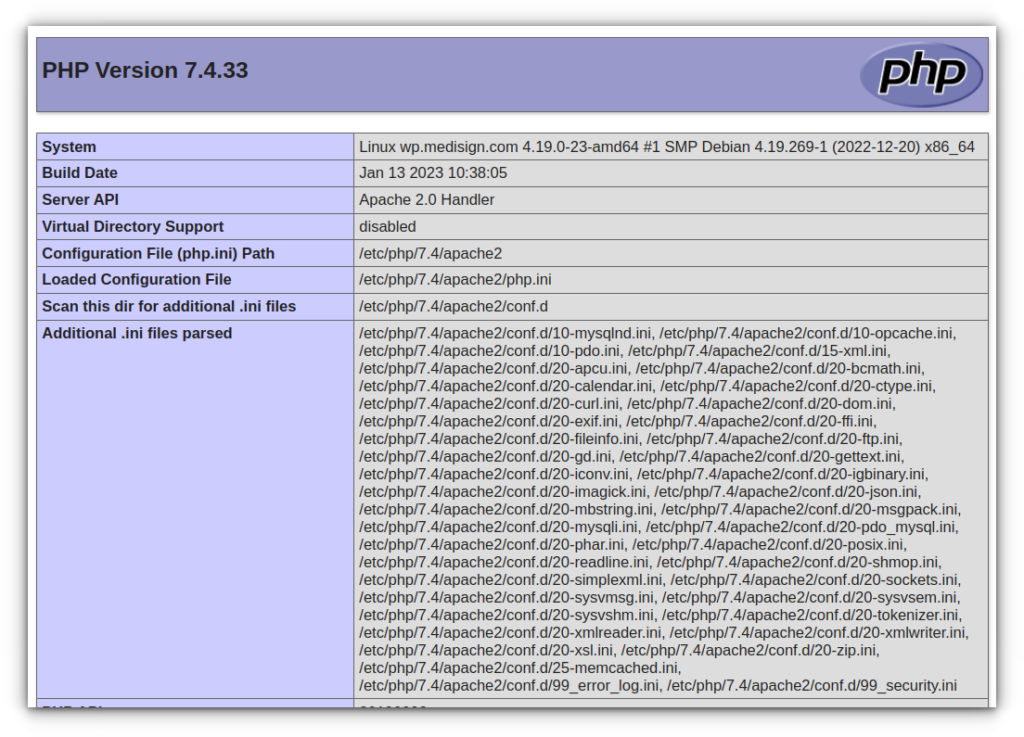
php.ini là nơi định hình hành vi của PHP tại thời điểm chạy. Các tùy chọn trong php.ini cho phép điều chỉnh cách PHP xử lý dữ liệu người dùng, cách quản lý tài nguyên, và cách tối ưu hiệu suất thông qua OPcache. Trong phần Open Cache (OPcache), các tham số như opcache.enable, opcache.memory_consumption, opcache.validate_timestamps và các tham số liên quan khác đóng vai trò chính trong việc quyết định cách PHP biên dịch và lưu trữ mã nguồn dưới dạng opcode để tăng tốc thực thi.
OPcache là một phần cấu hình runtime của PHP và có nhiều tùy chọn để tinh chỉnh. Những tham số này được mô tả chi tiết trong tài liệu Runtime Configuration, cho thấy cách opcache.enable, opcache.memory_consumption, opcache.validate_timestamps và các tham số khác ảnh hưởng đến hành vi của hệ thống PHP tại runtime. Việc bật OPcache và thiết lập đúng các tham số giúp giảm tải CPU và tăng tốc đáp ứng cho các request đồng thời. Nguồn tham khảo cho các tham số OPcache và cách chúng được mô tả trong php.ini được trình bày trong phần phụ lục của tài liệu này.
Yêu cầu và chuẩn bị
Đối với Ubuntu 20.04+, hệ thống áp dụng stack Apache và PHP-FPM cho môi trường Shared Hosting. Trong khối tài liệu này khuyến nghị bật OPcache và tùy biến các tham số liên quan ở mức phù hợp với tải trọng và giới hạn tài nguyên của máy chủ, sao cho vừa đảm bảo an toàn vừa tối ưu hiệu suất phục vụ nhiều tài khoản hosting cùng lúc. Nhắc lại rằng OPcache là một phần của runtime configuration và có các tham số có thể được bật/tắt và điều chỉnh thông qua php.ini, với các tham số chủ đạo được liệt kê và mô tả trong phần cấu hình OPcache của tài liệu này.
Cấu hình chính cho php.ini
Một phần cấu hình hardening cho php.ini tập trung vào OPcache và các tham số liên quan đến hành vi runtime. Dưới đây là danh sách các tham số OPcache quan trọng và giá trị tham khảo dựa trên tài liệu Runtime Configuration. Hãy áp dụng chúng vào php.ini của PHP-FPM (hoặc thông qua các pool cấu hình nếu phù hợp với hệ thống của bạn).
opcache.enable=1
opcache.enable_cli=0
opcache.memory_consumption=128
opcache.interned_strings_buffer=8
opcache.max_accelerated_files=10000
opcache.max_wasted_percentage=5
opcache.use_cwd=1
opcache.validate_timestamps=1
opcache.revalidate_freq=2
opcache.save_comments=1
opcache.fast_shutdown=0
opcache.file_cache_consistency_checks=1
opcache.lockfile_path /tmp
opcache.opt_debug_level=0
opcache.jit disable
opcache.jit_buffer_size 64M
Ghi chú về các tham số:
– opcache.enable=1: Bật OPcache để lưu trữ và phục hồi opcode, giúp tăng tốc xử lý các yêu cầu PHP.
– opcache.enable_cli=0: Tắt OPcache cho CLI, tránh rò rỉ bộ nhớ và tăng tính ổn định cho các tác vụ dòng lệnh nếu có.
– opcache.memory_consumption=128: Dung lượng bộ nhớ dùng cho opcode cache, sử dụng 128 MB làm mặc định cho môi trường có tải trung bình đến cao.
– opcache.interned_strings_buffer=8: Dung lượng bộ nhớ cho các chuỗi nội dung được interned, giúp tối ưu tham chiếu chuỗi trong quá trình biên dịch.
– opcache.max_accelerated_files=10000: Giới hạn số lượng file PHP được cache để đáp ứng số lượng file code được tải đồng thời.
– opcache.max_wasted_percentage=5: Tỉ lệ phần trăm tối đa của bộ nhớ cache có thể tạm thời bị loại bỏ do thiếu mã nguồn hợp lệ.
– opcache.use_cwd=1: Tối ưu hóa caching theo thư mục làm việc hiện tại để tránh cache chung cho toàn bộ hệ thống.
– opcache.validate_timestamps=1: Theo dõi sự thay đổi timestamp của files để làm mới cache khi có thay đổi.
– opcache.revalidate_freq=2: Số lần lược bỏ cache hợp lệ trước khi làm mới khi có thay đổi file với tần suất thấp.
– opcache.save_comments=1: Lưu lại các nhận xét trong opcode để hỗ trợ debugging và tooling.
– opcache.fast_shutdown=0: Tắt chế độ shutdown nhanh để đảm bảo an toàn khi xử lý nhiều request đồng thời.
– opcache.file_cache_consistency_checks=1: Bật kiểm tra tính nhất quán cho cache file ở cấp độ hệ thống.
– opcache.lockfile_path /tmp: Định vị đường dẫn lockfile cho OPcache để hỗ trợ đồng bộ hóa truy cập cache trong môi trường đa tiến trình.
– opcache.opt_debug_level=0: Thiết lập mức debug tối thiểu cho OPcache để cân bằng giữa hiệu suất và khả năng chẩn đoán.
– opcache.jit=disable và opcache.jit_buffer_size=64M: Vô hiệu hóa JIT hoặc tinh chỉnh khi cần, phù hợp cho môi trường chia sẻ với PHP-FPM.
Những giá trị trên là tham khảo từ tài liệu Runtime Configuration và có thể điều chỉnh tùy theo phiên bản PHP đang chạy và tải trọng thực tế. Trong quá trình triển khai, nên bắt đầu với các giá trị an toàn và theo dõi hiệu suất, sau đó tinh chỉnh dần dần.
Bảo mật và thực hành an toàn liên quan đến php.ini
Các khía cạnh an ninh liên quan đến PHP có thể được ảnh hưởng bởi php.ini ở nhiều mức độ. Các nội dung sau đây dựa trên phân tích của tài liệu liên quan đến bảo mật và cấu hình PHP:
- Quản lý dữ liệu người dùng và xử lý dữ liệu người nộp: php.ini có vai trò quyết định cách PHP xử lý dữ liệu người dùng, vì vậy nên giới hạn các cơ chế nhận dữ liệu và đảm bảo xác thực người dùng ở mức ứng dụng. Đảm bảo các tham số như báo cáo lỗi được kiểm soát để không làm lộ thông tin nhạy cảm ra bên ngoài.
- Bảo mật báo cáo lỗi: Thiết lập sao cho lỗi hệ thống không bị hiển thị công khai, và log được ghi lại cho phân tích sự cố sau này. Yếu tố này nằm ở mục giới thiệu an ninh tổng thể và ảnh hưởng tới chuyển đổi cấu hình php.ini theo hướng an toàn.
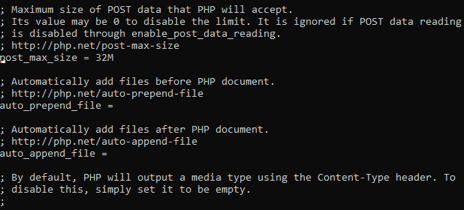
- Quản lý dữ liệu nhúng và tải lên tệp: PHP có cơ chế xử lý file uploads và dữ liệu người dùng; php.ini được dùng để giới hạn kích thước tải lên và các tham số liên quan tới xử lý dữ liệu người dùng.
- Ẩn thông tin và giảm fingerprint hệ thống: trong khía cạnh an ninh, ẩn thông tin về môi trường thực thi cũng là mục tiêu có thể được cân nhắc thông qua php.ini và cấu hình máy chủ.
Những nguyên tắc này được mô tả trong tài liệu Security Introduction đi kèm với tài liệu Runtime Configuration và được áp dụng đồng bộ với các tham số OPcache ở trên để tối ưu cả bảo mật lẫn hiệu suất trong môi trường shared hosting.
Hiệu suất và tối ưu hóa
OPcache đóng vai trò then chốt trong tối ưu hiệu suất của PHP khi chạy trên PHP-FPM và Apache. Việc bật OPcache và tinh chỉnh các tham số liên quan có thể giảm tải CPU và cải thiện thời gian đáp ứng cho nhiều người dùng cùng lúc. Trong tài liệu Runtime Configuration, OPcache được trình bày với các tham số có thể điều chỉnh và ảnh hưởng trực tiếp đến cách PHP biên dịch và lưu trữ opcode. Việc tối ưu dựng lên từ các tham số như bộ nhớ cache, số file được cache, thời gian làm mới cache và cách thức xử lý các file có thể tạm thời ảnh hưởng tới hiệu suất theo từng trường hợp cụ thể.
Đối với môi trường Ubuntu 20.04+ chạy Apache và PHP-FPM, việc tối ưu hóa OPcache nên cân nhắc các yếu tố sau:
- Dung lượng bộ nhớ cho OPcache phụ thuộc tải trọng và giới hạn tài nguyên. Với số lượng file code và số request đồng thời, việc tăng memory_consumption có thể cải thiện hiệu suất, lưu ý không vượt quá giới hạn RAM có sẵn để tránh swapping.
- Kiểm soát thời gian làm mới cache và theo dõi timestamp để cân bằng giữa tính đồng bộ và hiệu suất. Tham số validate_timestamps và revalidate_freq cho phép bạn xác định tần suất làm mới khi có sự thay đổi mã nguồn.
- Khung chữ ký và cấu hình JIT (Just-In-Time compilation) có thể được tắt hoặc bật tùy phiên bản và workload. Trong môi trường chia sẻ, khởi đầu với chế độ disable JIT là an toàn, và kích hoạt khi có nhu cầu tối ưu hóa thêm.
Việc áp dụng các tham số OPcache như đã nêu sẽ giúp tối ưu hiệu suất cho các ứng dụng chạy trên PHP-FPM và phục vụ đồng thời nhiều tài khoản hosting mà không làm tăng rủi ro bảo mật. Đây là một trong các bước then chốt trong quá trình hardening php.ini cho môi trường shared hosting.
Giám sát và quan sát hiệu suất
Việc theo dõi trạng thái hoạt động của OPcache và PHP là cần thiết để xác định hiệu suất và mức độ ổn định của hệ thống. Trong thực tiễn, hãy theo dõi các chỉ số liên quan đến OPcache và log lớp runtime để có thể điều chỉnh cấu hình khi tải trọng thay đổi. Các tham số OPcache được mô tả ở mục trên là cơ sở để bạn thiết lập và so sánh khi phân tích hiệu suất hệ thống, đồng thời kết hợp với các biện pháp bảo mật đã đề cập ở phần trước.
Kiểm tra và xác thực cấu hình
Để xác nhận rằng cấu hình php.ini đã được áp dụng đúng, bạn có thể thực hiện các bước sau đây, dựa trên các tham số OPcache đã thiết lập ở trên:
- Xác nhận OPcache đang được bật và các tham số chính đang có hiệu lực bằng cách kiểm tra cấu hình runtime của PHP thông qua các công cụ quản trị hoặc bằng cách xem các tệp log phù hợp của PHP-FPM và Apache.
- Kiểm tra tính hợp lệ của các file code và thời gian làm mới cache, đảm bảo rằng hệ thống sẽ làm mới đúng theo thiết lập revalidate_freq và validate_timestamps để đảm bảo rằng các bản vá và cập nhật mã nguồn được phản ánh kịp thời.
- Đảm bảo rằng các tham số bảo mật liên quan đến báo cáo lỗi và ghi log được áp dụng đúng cách để ngăn rò rỉ thông tin nhạy cảm ra bên ngoài.
Những thực hành trên đều dựa trên nguyên tắc được mô tả trong tài liệu Runtime Configuration và Security Introduction và áp dụng một cách nhất quán với hệ thống Apache và PHP-FPM trên Ubuntu 20.04+.
Checklist vận hành cuối cùng
-
<li Xác định phiên bản PHP đang chạy và đường dẫn tới php.ini cho PHP-FPM và Apache để áp dụng cấu hình đúng cho mỗi pool hoặc vhost nếu cần.
<li Bật OPcache và áp dụng các tham số đã liệt kê ở mục Cấu hình chính.
<li Giới hạn và định lượng tải: thiết lập memory_consumption phù hợp với RAM sẵn có và tải trọng tối đa dự kiến.
<li Thiết lập revalidate_freq và validate_timestamps để cân bằng giữa tính đúng đắn của cache và hiệu suất.
<li Đảm bảo an toàn báo cáo lỗi và không hiển thị thông tin nhạy cảm cho người dùng.
<li Theo dõi hiệu suất sau khi triển khai và điều chỉnh tham số OPcache theo nhu cầu.
Kết luận
Hardening php.ini cho môi trường Shared Hosting là một phần quan trọng của quy trình quản trị hệ thống. Việc bật và tối ưu OPcache thông qua các tham số trong php.ini không chỉ giúp cải thiện hiệu suất phục vụ nhiều tài khoản mà còn góp phần tăng cường bảo mật bằng cách quản lý cách PHP xử lý và cache mã nguồn. Với Ubuntu 20.04+ và stack Apache cùng PHP-FPM, bạn có thể áp dụng các tham số OPcache được mô tả ở đây và điều chỉnh dựa trên tải trọng thực tế của máy chủ. Hãy duy trì một chu kỳ kiểm tra cấu hình và hiệu suất để đảm bảo hệ thống luôn ở trạng thái an toàn và tối ưu nhất cho người dùng cuối.







![[Thực chiến] Prometheus Alertmanager: Thiết lập cảnh báo thông minh trên Ubuntu 20.04+](https://thanhnh.id.vn/wp-content/uploads/2026/04/monitoring-ubuntu-20-04-plus-prometheus-alertmanager-thiet-lap-canh-bao-thong-minh.png)